Mysql的Binlog原理学习
一、背景
作为开发人员,mysql在开发过程中必不可少,有些公司,打击数据库账号权限控制做的不是很到位,因此,常常会有数据库、表被误删的情况。
当数据库被删时,如何来恢复呢?最常用的一般就是通过mysql的binlog。那如何操作,原理又是什么?一起来学习一下。
二、Mysql的Binlog了解
2.1 什么是二进制日志
binlog是记录所有数据库表结构变更(例如CREATE、ALTER TABLE…)以及表数据修改(INSERT、UPDATE、DELETE…)的二进制日志。
binlog不会记录SELECT和SHOW这类操作,因为这类操作对数据本身并没有修改,但你可以通过查询通用日志来查看MySQL执行过的所有语句。
二进制日志包括两类文件:二进制日志索引文件(文件名后缀为.index)用于记录所有的二进制文件,二进制日志文件(文件名后缀为.00000*)记录数据库所有的DDL和DML(除了数据查询语句)语句事件。
2.2 什么是事务日志
innodb事务日志包括Redo log和undo log。
undo log指事务开始之前, 在操作任何数据之前,首先将需操作的数据备份到一个地方
Redo log指事务中操作的任何数据,将最新的数据备份到一个地方
事务日志的目的:实例或者介质失败,事务日志文件就能派上用场。
1.Redo log不是随着事务的提交才写入的,而是在事务的执行过程中,便开始写入redo 中。具体 的落盘策略可以进行配置 。防止在发生故障的时间点,尚有脏页未写入磁盘,在重启mysql服务的时候,根据 Redo log进行重做,从而达到事务的未入磁盘数据进行持久化这一特性。RedoLog是为了实现事务的持久性而出现的产物

2.undo log用来回滚行记录到某个版本。事务未提交之前,Undo保存了未提交之前的版本数据,Undo中的数据可作为数据旧版本快照供其他并发事务进行快照读。是为了实现事务的原子性而出现的产物,在Mysql innodb存储引擎中用来实现多版本并发控制

Redolog知识补充
指定Redo log 记录在{datadir}/ib\_logfile1&ib\_logfile2 可通过innodb\_log\_group\_home\_dir 配置指定 目录存储
一旦事务成功提交且数据持久化落盘之后,此时Redo log中的对应事务数据记录就失去了意义,所以Redo log的写入是日志文件循环写入的
指定Redo log日志文件组中的数量 innodb_log_files_in_group 默认为2
指定Redo log每一个日志文件最大存储量innodb_log_file_size 默认48
指定Redo log在cache/buffer中的buffer 池大小innodb_log_buffer_size 默认16Redo buffer 持久化Redo log 的策略, Innodb_flush_log_at_trx_commit:
取值 0 每秒提交 Redo buffer --> Redo log OS cache -->flush cache to disk[可能丢失一秒 的事务数据]
取值 1 默认值,每次事务提交执行Redo buffer --> Redo log OS cache -->flush cache to dis[ 最安全,性能最差的方式]
取值 2 每次事务提交执行Redo buffer --> Redo log OS cache 再每一秒执行 ->flush cache t disk操作
什么是快照读和当前读
快照读:SQL读取的数据是快照版本,也就是历史版本,普通的SELECT就是快照读 innodb快照读,数据的读取将由 cache(原本数据) + undo(事务修改过的数据) 两部分组成
当前读:SQL读取的数据是最新版本。通过锁机制来保证读取的数据无法通过其他事务进行修改 UPDATE、DELETE、INSERT、SELECT … LOCK IN SHARE MODE、SELECT … FOR UPDATE都是 当前读
Undo + Redo事务的简化过程
假设有A、B两个数据,值分别为1,2,开始一个事务,事务的操作内容为:把1修改为3,2修改为4,那么实际的记录如下(简化):
1 | |
二进制日志处理事务和非事务性语句的区别
在事务性语句(update)执行过程中,服务器将会进行额外的处理,在服务器执行时多个事务是并行执行的,为了把他们的记录在一起,需要引入事务日志的概念。在事务完成被提交的时候一同刷新到二进制日志。对于非事务性语句(insert,delete)的处理。遵循以下3条规则:
1)如果非事务性语句被标记为事务性,那么将被写入重做日志。
2)如果没有标记为事务性语句,而且重做日志中没有,那么直接写入二进制日志。
3)如果没有标记为事务性的,但是重做日志中有,那么写入重做日志。
注意如果在一个事务中有非事务性语句,那么将会利用规则2,优先将该影响非事务表语句直接写入二进制日志。
XA的概念
XA(分布式事务)规范主要定义了(全局)事务管理器(TM: Transaction Manager)和(局部)资源管理器(RM: Resource Manager)之间的接口。XA为了实现分布式事务,将事务的提交分成了两个阶段:也就是2PC (tow phase commit),XA协议就是通过将事务的提交分为两个阶段来实现分布式事务。
两阶段
1)prepare 阶段
事务管理器向所有涉及到的数据库服务器发出prepare”准备提交”请求,数据库收到请求后执行数据修改和日志记录等处理,处理完成后只是把事务的状态改成”可以提交”,然后把结果返回给事务管理器。即:为prepare阶段,TM向RM发出prepare指令,RM进行操作,然后返回成功与否的信息给TM。
2)commit 阶段
事务管理器收到回应后进入第二阶段,如果在第一阶段内有任何一个数据库的操作发生了错误,或者事务管理器收不到某个数据库的回应,则认为事务失败,回撤所有数据库的事务。数据库服务器收不到第二阶段的确认提交请求,也会把”可以提交”的事务回撤。如果第一阶段中所有数据库都提交成功,那么事务管理器向数据库服务器发出”确认提交”请求,数据库服务器把事务的”可以提交”状态改为”提交完成”状态,然后返回应答。即:为事务提交或者回滚阶段,如果TM收到所有RM的成功消息,则TM向RM发出提交指令;不然则发出回滚指令。
- 外部与内部XA
MySQL中的XA实现分为:外部XA和内部XA。前者是指我们通常意义上的分布式事务实现;后者是指单台MySQL服务器中,Server层作为TM(事务协调者,通常由binlog模块担当),而服务器中的多个数据库实例作为RM,而进行的一种分布式事务,也就是MySQL跨库事务;也就是一个事务涉及到同一个MySQL服务器中的两个innodb数据库(目前似乎只有innodb支持XA)。内部XA也可以用来保证redo和binlog的一致性问题。
事务日志与二进制日志的一致性问题
我们MySQL为了兼容其它非事务引擎的复制,在server层面引入了 binlog, 它可以记录所有引擎中的修改操作,因而可以对所有的引擎使用复制功能; 然而这种情况会导致Redo log与binlog的一致性问题;MySQL通过内部XA机制解决这种一致性的问题。
第一阶段:InnoDB prepare, write/sync Redo log;binlog不作任何操作;
第二阶段:包含两步,
1> write/sync Binlog;
第1步执行完成之后,binlog已经写入,MySQL会认为事务已经提交并持久化了(在这一步binlog就已经ready并且可以发送给订阅者了)。在这个时刻,就算数据库发生了崩溃,那么重启MySQL之后依然能正确恢复该事务。在这一步之前包含这一步任何操作的失败都会引起事务的rollback。
2> InnoDB commit (commit in memory);
第2步大部分都是内存操作(注意这里的InnoDB commit不是事务的commit),比如释放锁,释放mvcc相关的read view等等。MySQL认为这一步不会发生任何错误,一旦发生了错误那就是数据库的崩溃,MySQL自身无法处理。这个阶段没有任何导致事务rollback的逻辑。在程序运行层面,只有这一步完成之后,事务导致变更才能通过API或者客户端查询体现出来。
当然在mysql5.6之后引入了组提交的概念,可以在IO性能上进行一些提升,但总体的执行顺序不会改变。
下面的一张图,说明了MySQL在何时会将binlog发送给订阅者。
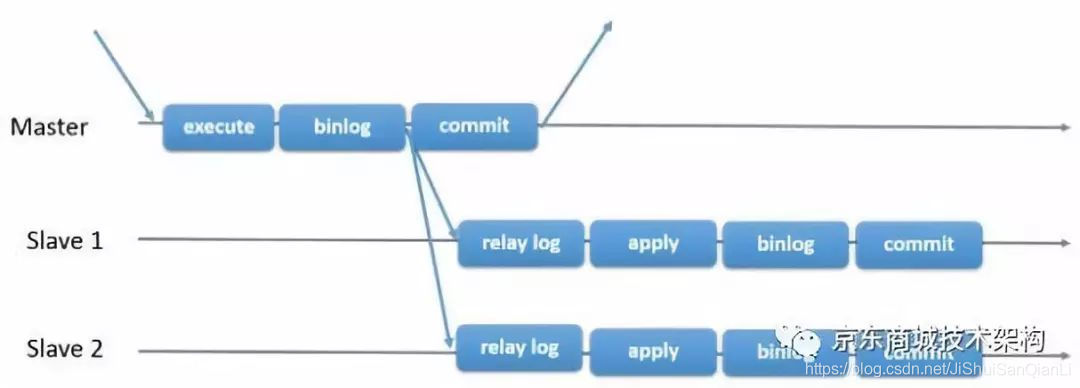
MySQL会在binlog落盘之后会立即将新增的binlog发送给订阅者以尽可能的降低主从延迟
如何开启mysql的binlog
1 | |
log-bin=mysql-bin #添加这一行就ok
binlog-format=ROW #选择row模式
server_id=1 #配置mysql replaction需要定义,不能和canal的slaveId重复
Binlog常见格式
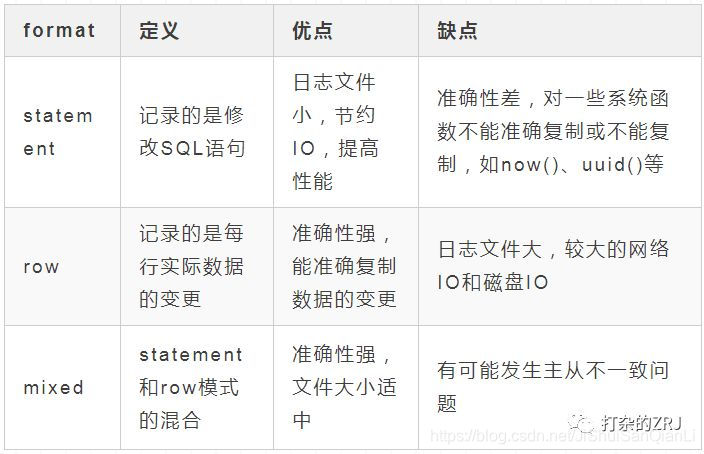
业内目前推荐使用的是row模式,准确性高,虽然说文件大,但是现在有SSD和万兆光纤网络,这些磁盘IO和网络IO都是可以接受的。
在innodb里其实又可以分为两部分,一部分在缓存中,一部分在磁盘上。这里业内有一个词叫做刷盘,就是指将缓存中的日志刷到磁盘上。跟刷盘有关的参数有两个个:sync_binlog和binlog_cache_size。这两个参数作用如下
binlog_cache_size: 二进制日志缓存部分的大小,默认值32k
sync_binlog=[N]: 表示每多少个事务写入缓冲,刷一次盘,默认值为0
注意两点:
(1)binlog_cache_size设过大,会造成内存浪费。binlog_cache_size设置过小,会频繁将缓冲日志写入临时文件。
(2)sync_binlog=0:表示刷新binlog时间点由操作系统自身来决定,操作系统自身会每隔一段时间就会刷新缓存数据到磁盘,这个性能最好。sync_binlog=1,代表每次事务提交时就会刷新binlog到磁盘,对性能有一定的影响。sync_binlog=N,代表每N个事务提交会进行一次binlog刷新。
另外,这里存在一个一致性问题,sync_binlog=N,数据库在操作系统宕机的时候,可能数据并没有同步到磁盘,于是再次重启数据库,会带来数据丢失问题。
mysql的binlog是多文件存储,定位一个LogEvent需要通过binlog filename + binlog position,进行定位
table_map event & write_rows event
这两个event是在binlog_format=row的时候使用,设置binlog_format=row,然后创建一个测试表
CREATE TABLE `trow` ( `i` int(11) NOT NULL, `c` varchar(10) DEFAULT NULL, PRIMARY KEY (`i`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1`
执行语句INSERT INTO trow VALUES(1, NULL), (2, ‘a’),这个语句会产生一个query event,一个table_map event、一个write_rows event以及一个xid event。
如何使用bin-log
修改mysql配置文件/etc/my.cnf
1 | |
检查开启状态
1 | |
如果得到如下(log_bin | ON)表示正常开启,如下:
1 | |
模拟删库
通过 reset master;将数据库历史的binlog文件还原,然后新增库 test 新增表 test;
新增一条记录
查看binlog日志文件,可以发现已经记录了日志。
然后删除库,也会进行记录。 
数据恢复
通过mysql提供的 mysqlbinlog 命令查看日志文件,找到需要恢复的位子。
1 | |
可以看到一些库以及表的信息。
选择需要恢复的内容,并记录行号。
通过以下命令,进行恢复(恢复之前需要新建一个和原来一样的库)
1 | |
效果如下:
常用的数据库订阅开源框架原理
1.原理

- 框架模拟mysql slave的交互协议,伪装自己为mysql slave,向mysql master发送dump协议
- mysql master收到dump请求,开始推送binary log给slave(也就是canal)
- 框架解析binary log对象(原始为byte流)
2.框架
2.1、mysql-binlog-connector-java(https://github.com/shyiko/mysql-binlog-connector-java)
目前开源的 CDC (change data capture)工具,如 Zendesk maxwell、Redhat debezium、LinkedIn Databus 等都底层依赖
mysql-binlog-connector-java或者其前身 open-replicator
不需要独立部署
稳定性不是很好,时间久了会出现connetion lost的情况
2.2、canal (https://github.com/alibaba/canal)
需要独立部署canal server服务
canal 已在阿里云推出商业化版本 数据传输服务DTS, 开通即用,免去部署维护的昂贵使用成本。DTS针对阿里云RDS、DRDS等产品进行了适配,解决了Binlog日志回收,主备切换、VPC网络切换等场景下的订阅高可用问题。同时,针对RDS进行了针对性的性能优化。
HA机制设计
canal的ha分为两部分,canal server和canal client分别有对应的ha(主备模式)实现
- canal server: 为了减少对mysql dump的请求,不同server上的instance要求同一时间只能有一个处于running,其他的处于standby状态.
- canal client: 为了保证有序性,一份instance同一时间只能由一个canal client进行get/ack/rollback操作,否则客户端接收无法保证有序

canal 1.1.1版本之后, 默认支持将canal server接收到的 binlog数据直接投递到MQ, 目前默认支持的MQ系统有:
Kafka,RocketMQ。1.1.3版本下修复了投递MQ模式,canal server HA在切换后不生效
参考文档: